Mathematics is an area of knowledge, which includes the study of such topics as numbers, formulas and related structures, shapes and spaces in which they are contained, and quantities and their changes. There is no general consensus about its exact scope or epistemological status. However, it is extremely labourious and time-consuming but necessary and is sometimes (albeit very rarely) interesting.
Neural Networks are somewhat interesting. Everyone kind of knows the math behind NNs (the gist of it). It was taught in CS5131 to a very limited extent but not many know about the full math behind deep and convolutional neural networks. I mean people get that it has something to do with backpropogation or whatever, but how do you scale it up to multiple value and multiple derivatives. As you will come to learn, these derivations are incredibly computationally intensive and time-consuming, especially during implementation. But I have done it because I care about AppVenture and I want to help the casual onlooker understand the many trials and tribulations a simple layer goes through to deliver what we should consider peak perfection. It was a fun but painful exercise and I gained a deeper understanding of the mathematical constructs that embody our world. Anyways, let's start out with a referesher. Warning that Matrix Math lurks ahead, so tread with caution. This is deeper than CS5131 could have ever hoped to cover, so you will learn some stuff with this excercise. This first part is about the math behind deep neural networks.
This article is written with some assumed knowledge of the reader but it is not that bad for most CS students especially since NNs are baby level for the most part. Nonetheless, assumed knowledge is written below.
Deep Neural Network (How to implement + basic understanding of the math)
Gradient Descent
Linear Algebra
If you don't know this stuff, all you really need to do is read an introduction to linear algebra, understand how matrices and vectors are multiplied and watch 3b1b's series on machine learning.
Let's start by importing our bff for life, Numpy.
>>>import numpy as np
Numpy is introduced in CS4132 (or PC6432 for some reason), but for a quick summary, it is a Linear Algebra library, which means it is VERY useful in this task.
Gradient Descent Example (Linear System Solution)
Observe the following series of mathematical equations:
4a+2b3a+8b=22=49
Despite the fact that solving these is pretty easy (as we learnt in Year 1), let's try going with a different solution from what is usually portrayed. Let's try using gradient descent.
If you remember, Gradient Descent is a method used to solve any sort of equation by taking steps towards the real value by using calculus to predict the direction and size of the step. Essentially if you remember in calculus, the minimum of the graph will have a tangent of slope 0 and hence we can understand the direction of these "steps" to solve the problem. We just need a function where the derivative and function result approach 0 as you get closer to the true solution. This function is known as the objective function.
As you probably know, a linear equation is written as such:
Ax−b=0
where A is a known square matrix, b is a known vector and x is an unknown vector.
In this case, for the objective function we will use Linear Least Squares (LLS) function as it is an accurate thing to minimize in this case written below.
F(x)=∣∣Ax−b∣∣22
Matrix Calculus
Now, what do the weird lines and two occurences of "2" above mean and how exactly do we calculate the derivative of a scalar in terms of a vector? Well we have to learn matrix calculus, a very peculiar domain of math that is very torturous. Ideally, you want to avoid this at all cost, but I will do a gentle walk through this stuff.
Firstly, let's revise derivatives wth this simple example:
ydxdy=sin(x2)+5=dxd(sin(x2)+5)=2xcos(x2)
For functions with multiple variables, we can find the partial derivative with respect to each of the variables, as shown below:
f(x,y)∂x∂(f(x,y))∂y∂(f(x,y))=3xy+x2=3y+2x=3x
A thing to understand is that vectors are just a collection of numbers, so an n-sized vector will have n partial derivatives if the function is f:Rn→R (the derivative is known as the gradient). But do we represent these n partial derivatives as a column vector or row vector?
Well, both actually can work (even if you think of a vector as a column vector), the first version is called the denominator layout and the second one is called the numerator layout. They are both transpositions of each other. For gradient descent the denominator layout is more natural because for standard practice because we think of a vector as a column vector. I also prefer the denominator layout. However, the numerator layout follows the rules of single variable calculus more normally and will be much easier to follow. For example, matrices do not have commutative multiplication so the direction you chain terms matters. We naturally think of chaining terms to the back and this is true for numerator layout but in denominator layout terms are chained to the front. Product rule also is more funny when it comes to denom layout. So moving forward we will stick with the numerator layout and transpose the matrix or vector once the derivative is found. We will also stick to column vectors.
First lets look at the Ax−b term and we will see why the derivative is so and so with a simple 2×2 case. Ax−b is a f:Rn→Rn and hence the derivative will be a matrix (known as the Jacobian to many). Lets first, see the general equation and work it out for every value.
We see that it is kind of the same with single variable, where if we have f(x)=ax, then f′(x)=a where a is constant.
Now we look at the lines and "2"s. This is a common function known as the euclidean norm or 2-norm.
∥x∥2:=x12+⋯+xn2
We then square it giving rise to the second "2". Now we define and do the same thing we did with Ax−b, ∥y∥22 is f:Rn→R. Hence, the derivative is a row vector.
z=∥y∥22=y12+y22
Now we calculate the Gradient (remember that it is transposed) by calculating the individual derivative for every value.
As we can see from that last step, its pretty complex an expression, but you can see how neat matrix notation is as compared to writing all that out and you see how matrix calculus works. With numerator layout, its very similar to single-variable but with a few extra steps.
I then transpose the derivative back into the denominator layout written below. The step function is also written below which we will use for the gradient descent.
F(x)∇F(x)xn+1=∣∣Ax−b∣∣2=2AT(Ax−b)=xn−γ∇F(xn)
where γ is the learning rate, we need a small learning rate as it prevents the function from taking large steps and objective functions tend to overblow the "true" error of a function.
We can now implement this in code form for a very simple linear system written below:
>>> A = np.array([[1,3,2,-1],[5,2,1,-2],[0,1,2,4],[1,1,-1,-3]], dtype=np.float64)>>> A
array([[1.,3.,2.,-1.],[5.,2.,1.,-2.],[0.,1.,2.,4.],[1.,1.,-1.,-3.]])
b=⎣⎢⎢⎢⎡9424−12⎦⎥⎥⎥⎤
>>> b = np.array([[9],[4],[24],[-12]], dtype=np.float64)>>> b
array([[9.],[4.],[24.],[-12.]])
x=⎣⎢⎢⎢⎡wxyz⎦⎥⎥⎥⎤
>>> x = np.random.rand(4,1)>>> x
array([[0.09257854],[0.16847643],[0.39120624],[0.78484474]])
>>>defobjective_function_derivative(x):return2* np.matmul(A.T, np.matmul(A,x)- b)
In this case, I implemented an arbritary learning rate and arbritary step count. In traditional non-machine learning gradient descent, the learning rate changes per step and is determined via a heuristic such as the Barzilai–Borwein method, however this is not necessary as gradient descent is very robust. I used an arbritary step count for simplicity but you should ideally use some sort of boolean condition to break the loop such as F(x)<0.01.
xn+1=xn−γ∇F(xn)
>>> learning_rate =0.01>>>for i inrange(5000):
x -= learning_rate * objective_function_derivative(x)>>> x
array([[1.],[2.],[3.],[4.]])
And to check, we now use a simple matrix multiplication:
As you can see, this is just a linear system much like the one showed in the example and it becomes very simple.
zac=Wx+b=σ(z)=n1∣∣a−y∣∣22
From our work earlier we know that:
∂b∂z∂x∂z∂a∂c=I=W=n2(a−y)T
However we have once again hit a speedbump. How do we find the derivative of a vector z with respect to a matrix W? The function is of the form f:Rm×n→Rm. Hence, the derivative will be a third order tensor also known as a 3D matrix. (colloquially) But for now we will use a trick to dodge the usage of third order tensors because of the nature of the function Wx. For this example, I use m=3 and n=2 but its generalizable for any sizes.
We see that this is a pretty complex looking tensor but we see that a majority of the values are 0 allowing us to pull of an epic hack by considering the fact that at the end we are essentially trying to get a singular scalar value (the loss) and find the partial derivative of that wrt to W. There are some steps involved in getting from z to c but for simplicity instead of showing everything, we will condense all of this into a function f:Rn→R which is defined as c=f(z). In this case, we know the tensor values and we know the gradient and what the derivative should be. Hence, we now just evaluate it and see if we can see any property:
Wonderful, we have just found out this amazing method, where we just add x to the front. Normally this method is not possible but it is just possible in this special case as we dont have to consider terms such as ∂z2∂c∂w11∂z2 because they are just 0. It helps us dodge all the possibilites of tensor calculus (at least for now) and allows the NumPy multiplication to be much easier. f can also generalize for any vector to scalar function, not just the specific steps we make.
The next speedbump is much more easier to grasp than the last one, and that is element-wise operations. In this case, we have the activation function σ:Rn→Rn or σ:R→R, which looks like a sigmoid function, but this is just a placeholder function. It can be any R to R activation function, such as RELU(x)=max(x,0), or whatever else has been found in research, such as SMELU and GELU. Once again, we work it out for every single value, as shown below:
As you see, we can reduce this derivative to this specific value. I have used the diag operator which converts a vector to a diagonal matrix. Finally, after all this derivation (mathematically and figuratively) we can use chain rule to join everything together:
Now it is time to actually implement this network (finally).
Neural Network Implementation (XNOR Gate)
I couldn't find a good, but rather small dataset because most people really do like large datasets and are infuriated when they are not provided that like entitled brats normal people. So, instead, I decided that we will train our neural network to mimic the XNOR gate.
Oh no! Training? Testing? What is that? In all fairness, I am simply trying to show you that the mathematical functions that dictate neural networks as we have found above, fits perfectly with this task of a neural network, and that these neural networks that everyone hears about can really just mimic any function.
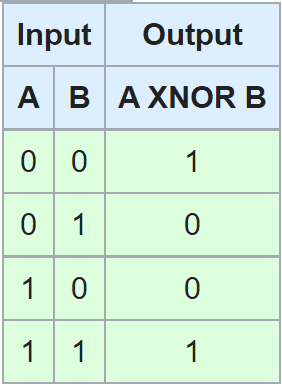
For those who do not know, the XNOR gates inputs and outputs are written above. It is pretty suitable for this example, because the inputs and outputs are all 0 and 1, hence it is fast to train and there is no bias in the data.
From here, let's try coding out the (x,y) pairs in NumPy:
data =[[np.array([[0],[0]], dtype=np.float64),np.array([[1]], dtype=np.float64)],[np.array([[0],[1]], dtype=np.float64),np.array([[0]], dtype=np.float64)],[np.array([[1],[0]], dtype=np.float64),np.array([[0]], dtype=np.float64)],[np.array([[1],[1]], dtype=np.float64),np.array([[1]], dtype=np.float64)]]
We then define a network structure. It doesn't have to be too complex because it is a pretty simple function. I decided on a 2→3→1 multi-layer perceptron (MLP) structure, with the sigmoid activation function.
Next, let's try coding out our mathematical work based off the following class:
Next I program gradient descent. There are 3 kinds of gradient descent when there are multiple datapoints, Stochastic, Batch and Mini-Batch. In Stochastic Gradient Descent (SGD), the weights are updated after a single sample is run. This will obviously cause your step towards the ideal value be very chaotic. In Batch Gradient Descent, the weights are updated after every sample is run, and the net step is the sum/average of all the ∇F(x), which is less chaotic, but steps are less frequent.
Of course, in real life, we can never know which algorithm is better without making an assumption about the data. (No Free Lunch Theorem) A good compromise is Mini-Batch Gradient Descent, which is like Batch Gradient Descent but use smaller chunks of all the datapoints every step. In this case, I use Batch Gradient Descent.
loss (1000/10000): 0.245
loss (2000/10000): 0.186
loss (3000/10000): 0.029
loss (4000/10000): 0.007
loss (5000/10000): 0.003
loss (6000/10000): 0.002
loss (7000/10000): 0.002
loss (8000/10000): 0.001
loss (9000/10000): 0.001
loss (10000/10000): 0.001
Voila! We have officially programmed Neural Networks from scratch. Pat yourself on the back for reading through this. And of course, if you bothered to code this out, try porting it over to different languages like Java, JS or even C (yikes why would anyone subjects themselves to that?).
In the next part, it is time for the actual hard part. Good luck!
References
A lot of people think I just collated a bunch of sources and rephrased, and honestly I walked into writing this thinking I would be doing just that. The problem is that many sources who have attempted to do this, only cover the single to multi-perceptron layer case and not the multi to multi-perceptron case. Which is pretty sad. The true math is hidden behind mountains of research papers that loosely connect to give the results of this blogpot which I am too incomponent to connect by myself. So, I just did the math myself. (The math may not be presented in this way but it works so it should be correct) Yes, it was a bit crazy, and it destroyed me to my core. This was a great character building moment for me. So these are the actual sources: